2016013212
第二小组 任杰
目录
6月29日:配置服务器环境
继前一日了解了项目目标并组装了任务所需工作站后,这一日的主要任务就是配置服务器端所需环境。
主要工作为:
- 安装并配置Python 3.5
- 在Python中安装并配置TensorFlow库
值得注意的是,Win10的权限管理较为严格,在我们所使用的那台新机器上,由于未知的配置原因,仅仅使用管理员模式运行也不能成功安装Python。最终问题的解决方法是,创建一个管理权限的explorer来运行安装程序。
在安装TensorFlow的过程中,也有值得注意的地方。我们的新机器虽然是n卡,但是也没装CUDA,所以GPU版的TensorFlow库是不能用了,虽然感觉很浪费机器资源……所以只能用CPU版的。CUDA比较巨大,而且安装不方便,希望下一次开设此挑战项目的时候能够在机器上预装CUDA。
此外,该机器虽然安装了MS VC++ Library,但是其中一个DLL文件版本不对导致TensorFlow安装失败,必须从外网找到合适版本的DLL置于System32来解决此问题。最烦人的是安装过程显示的错误信息与该实际问题毫无关系,不过StackOverflow上提供了很有效的解决方法。
6月30日:配置并熟悉PYNQ Board环境
这一天的工作与工作站本身无关了,主要是配置PYNQ。XILINX已经预先写入SD卡,PYNQ也配置好从SD卡启动,这给让我们可以快速开始工作。
PYNQ官网提供的指导非常详尽,只需要按照指示配置计算机直接连接PYNQ的以太网静态IP(192.168.2.0-255),就可以让PYNQ识别所连接的计算机。使用Webkit内核的浏览器访问PYNQ的地址和指定端口,就可以显示XILINX对计算机的界面。界面中提供的功能较多,我们没有一一研究,主要了解了Terminal和代码编译器。

LED项目

马信在操作
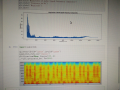
频谱图



在编译器中,我们依照示例输入、阅读并调试了LED灯程序和录音回放、频谱分析的两个程序。我虽然此前从未使用过Python,但是也很快理解了代码的大意。Python的可读性很强,很接近自然语言,而且代码的冗余信息很少,变量往往不需要声明可以直接赋值使用,这对于编写代码者来说是非常友好的。当然,在这么短的时间内,学通Python也一定是不可能的,所以输入和调试这些代码主要是了解处理声音数据时,常用的库、类和方法有哪些。根据指导书,除了基本的板载元件对应的类和方法(使用板载mic录音并储存文件),fft也是非常重要的,这能得到短时的频率分布;紧接着是通过plot得到频谱图,这是适合传输到服务器进行分析的数据。
代码中有一个思想非常有价值。因为PYNQ的性能有限,所以在fft前,程序先对音频进行降低采样率(码率)的处理,有利于快速计算结果。这种处理对于关键信息的损失很小,提高了效率,虽然不一定是必要的,但是是很有用的。
7月1日:熟悉TensorFlow
上午不幸迟到,不知道周末也要算迟到……
上午的任务主要是昨日延续,在PYNQ Board上做了一下使用Webcamera的一个项目。主要收获是了解了Pillow库的使用,除了代码中给出的打开文件、颜色空间的转换、旋转(open, convert, rotate)等,我们还了解了一下PIL的许多其他方法,比如裁切(crop),获取尺寸(size)等等。PIL库在图像处理上非常有用,mark住了。
接下来的一个项目复杂一些,是实时的图像边缘识别,这个也顺利跑下来了。闲得没事干的马信还把代码研究了一番。

图像旋转
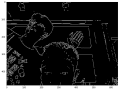
边缘识别


中间穿插了一些PYNQ板的介绍。大多数都是基础的计算机系统的知识,也就不说了。值得提的有两点,一个是PYNQ上是有可编程芯片的,第二是有类似Aduino上的那种针脚插入式的接口,接口可以自定义,以连接不同的传感设备,以拓展PYNQ的能力。
下午名义上的任务是在工作站上跑一个使用TensorFlow的程序,但是实际上大多时间还是用来配置环境了。主要问题是,老师了解到我的机器没有CUDA,就让我安装CUDA再重新配置TensorFLow。但是连接我们的工作站的那个交换机好像是有防火墙的,速度奇慢,从nVidia直接下载CUDA是不可能了。所以就一台机子一台机子的找。共享服务器上只找到CUDnn的库文件,没有CUDA。助教说共享服务器上应该是有CUDA安装文件的,但是迷之消失了。最后还是在一台机子上找到了这个庞大的文件,然而那台机子上传到共享服务器的速度也是只有两三兆,而我从共享服务器下载的速度就只有两三百K了,不可行。手机做媒介拷贝也不行,Win Server 2012因为安全性的原因好像不识别MTP设备。所以就用助教的闪存盘,拷贝进去后发现,我的这台机子识别不了这个闪存盘。至此已经下午四点多了,我,卒。
小小吐槽一下,我们用的这台新组装的机子安装的系统居然是雨林木风的,我以为这家公司五年前就销声匿迹了。然后盗版手段也非常低级,C盘里有一个文件夹Windows.Old,系统状态显示未注册,没跑了,这个显然是用去年win7/8/8.1免费可回滚升级win10的那版升级系统做的盗版系统,有可能仅仅是做了个镜像,然后嵌入个YLMF的logo,安上一堆给了钱的垃圾软件……何必呢,清华信息服务中心上有授权了的Windows镜像的我记得,安那个就好了。
继续说正事儿,因为安装CUDA的事算是吹了,所以我决定直接用CPU版的TensorFlow了。问题是一跑py,发现,发现连Pillow和scipy这些库都没装,那就装吧,装scipy的时候出依赖bug,装不上。真惨了,幸亏有助教在,给指了一条明路,把python卸载了,直接从TUNA下载Anaconda。这时候我才知道Anaconda原来是python集成了很多常用库和所需环境的一个版本,省去了大量配置的麻烦,没用过python的我算是吃了亏了……
配置完了后,跑代码,非常顺利,十轮,CPU上也是一秒不到的事,早知CPU也能这么快,何必折腾CUDA呢。我再看计算机配置,GTX970,12核3.5GHz i7-xxxxK,想想,相对来说这GPU也没有特别强啊,不如当时就直接跑CPU版本了。结果也在浏览器中看到了,不过用Chrome就加载不出,Edge可以。晚上的时候,马信又去了实验室,补跑了一下下午的工程,据他说,Chrome突然出现了问题,中文里混了许多方块乱码。这机子真是太诡异了。
中间穿插了一些理论讲解,都是比较基础的概念,就是提到了神经网络的结构和原理,这些东西在第四章里也都阐述了,就不罗嗦了。实际应用的时候,只要调用TensorFlow的方法就行了。
P.S. GFW又发力了,TensorFlow官网被墙了,得用VPN了。
7月2日:机器学习
从GitLab上获取所需代码后,又得到了预先处理过的音频文件。音频文件本来数量不多,经过加干扰就获得了一大批文件。
简单阅读了一下train.py和client.py,train.py中设定一个epoch包含3000个stage,然后循环执行100个epoch,除了第一个epoch外,都以上次保存的模型为checkpoint继续进行训练,这样就得到了许多checkpoint,可以选择在一定时候停止训练,可以得到阶段性的学习成果,也就是神经网络模型。train.py执行中只负责训练神经网络,而client.py负责读取音频文件并处理,通过端口feed给train.py。需要注意的是要使用管理员权限运行python,否则通过端口的数据传输会被拒绝。
训练开始(CPU)
满负荷运转
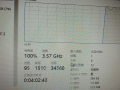
超……超频?!



上午离开前让CPU版的TensorFlow跑起来了,就离开了。初始的accuracy是0.04,基本上就是瞎蒙的概率;速度刚刚好是一个epoch耗时90分钟,下午回来又等了很久,同时以蜗牛网速下载着CUDA,CUDA安装完的时候,跑完了2.5个epoch,也就是完成了2次训练,得到了第二个神经网络模型,第二个模型的accuracy大概是0.52。这时候将进程终止,修改train.py,让它从第三轮epoch开始进行,同时把CPU版的TensorFlow用GPU版本替换了。下午离开的时候,第三轮跑了一半,accuracy已经升到0.67了。
我们用的机器的GPU是GTX970,不算特别尖端。跑一个epoch大概耗时1500s。而另一台用Titan的机器,跑一个epoch只要900s,速度几乎快了一倍。不过按照我们的速度,机器跑一个通宵,第二天回来的时候也应该能跑完相当可观的轮次数了,虽然越往后降低损失函数可能越不容易,但是据老师说14个epoch得到的模型已经有很高的准确度了。还是要感谢CLDNN算法的优势。
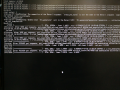
从第三轮继续训练(GPU)

在运行训练的间隙,我们折腾了一下一台闲置的工作站。本来装的是ubuntu,后又装了Win Server 2012,但是Server是空的,比较难配置,也就没去用它,然而ubuntu也出了问题,不能正确识别显卡,图形界面也进不去。在命令行下运行安装显卡驱动也出现错误,与运行着的X Server冲突,X Server却也是进不去的,最后干脆进入recovery, dpkg模式,将所有包都重装,最后结果还不知道,第二天再去折腾。
7月3日:Android终端部署
很早就到了实验室,发现一件很坑的事,这台机器设置了自动休眠,整个晚上都没有运行训练。一台台式工作站为什么会设置着休眠……只好重新启动进程,让电脑继续学习。
今日主要任务是将模型部署到移动终端,在这个项目中就是我们自己的android手机。当然首先计算机端要先有Android IDE。从官方下载Android Studio即可。Android Studio的工程结构,我十分不熟悉,一眼看过去基本上是懵逼的,所以当我们从GibLab下载的工程出现bug的时候,我也不知从何下手,看了半天也没看出个所以然。网上搜了一下,说是一段代码可能是多余的,那我就一删了之,结果是编译能继续进行了,但是又出现两个问题,显示两个深层目录下的两张图片无法访问。此外,试图使用虚拟机调试程序,但是IDE提示BIOS禁用了VT-x,无法运行虚拟机。重启进入BIOS,我只找到一个VT-d的选项,开启后IDE仍然报错,这个问题就暂时无解了。另外要补充一下,工程文件中需要补充TensorFlow提供的库和定义ABI的文件,从官网下载放置在工程目录中即可。

无法运行虚拟机

下午继续进行上午的工作。考虑到报错的内容有些莫名其妙,可能是外部的原因,首先进入报错的目录,发现目录是空的。试图在里面创建所需要的图片文件时,发现无法输入完整的文件名,文件名长度被限制。在外部目录创建该文件,再拷贝到目录内时,系统提示“该文件名对于此目录可能过长”,这时候问题就暴露出来了。我们下载工程文档的时候,浏览器/GitLab自动在文件名上加了一长串识别码或区分码之类的东西,使得文件目录名特别长。重新解压后,将目录名修改为较短的,再重新配置工程,发现可以顺利编译。至此,剩下的任务就是将工程部署到手机端。
我的Android UI封闭性较强,开启开发者模式较为麻烦,故用马信的Mi6(brand neeeeew)。好不容易找到type-C线后,将手机连接至计算机,将手机上的USB调试打开,然而Android Studio在手机上安装apk失败。再查看手机设置,USB安装被缺省关闭。试图开启,发现无法开启,这是新MIUI的bug?上MIUI论坛查了一下,四天前还有开发者在吐槽,无法开启USB安装,官方回复是bug正在修复。看来这个问题暂时无法解决了。助教提示可以先build出apk,然后将apk复制到手机目录。按此方法操作,我们成功地将程序部署到了手机,甚至不需要开启开发者模式。所以我们本来就不用调试这个程序,为什么要开启开发者模式?
识别效果不错,就是发现,至少在实验室环境下,实验室提供的模型无法有效地区分“上”和“下”。说“上”时,当“啊”的音较重时才能识别为上,如果“啊”的音不够强,而舌下气流声过强,就会识别为“下”。当然,这个模型识别的也不是单个的“上”和“下”,而是整段的文字,这个无法准确识别的问题也是体现在上下文整体之中的。训练数据中应该增加更多不同口音的人的数据,增加更多的不同噪声,这样虽然会让训练进度减缓,但是轮次数足够后,效果应该会更好。
最后尝试了将我们自己训练出的模型部署到工程中。指导手册中提供了一些TensorFlow下的转化为二进制数据与保存的代码,但是我们训练用的是Keras,保存的模型文件与TensorFlow保存的不同,所以要读取模型文件,只能使用KerasModel提供的各种方法,然而我们又没有找到在Keras下相应的转化为二进制数据的代码,也不能调用KerasModel创建的TensorFlow BackEnd的方法,所以这个问题就暂时无法解决了。
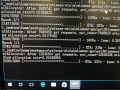
修改后一个epoch只需要1000s

另外,由于中间进行了重启,我需要重新启动训练,但是屡次启动失败。这个问题实际上是因为那个垃圾软件电脑管家导致的,但是一开始并不知情的助教尝试了不同的方法而无法解决,其中一个方法是修改client.py中最后一行的数据,这个数字代表这要创建的传输训练数据的线程数。问题解决后,我尝试了调整训练工程文件中的client.py。将线程数从14增加至32,结果发现在同一台机器上,跑一个epoch的速度大大增加,从1500s缩减至1000s,修改了线程数后GTX970都快赶上没修改时候Titan X的成绩了。助教表示他现在发现这个训练程序的设计还是有缺陷,因为线程数不够导致feed数据的速度赶不上显卡算力饱和的速度,显卡无法发挥出最大性能。我后来尝试将线程数继续增加,但是发现速度不再增加,可能32个数据传输的线程已经足够使得GTX970算力饱和了。助教又表示,这个训练程序其实可以不需要使用client.py将数据feed给train.py的模式,既然机器的内存有64G,完全可以将所有的数据传至内存,让显卡直接访问数据,这样就不会为CPU的性能所限制,特别是在CPU更弱的机器上,这样的结构优势是很明显的。
7月4日:模型部署与验证
今天可以说是自主学习最到位的一天了。为了将我们自己训练得到的keras权重文件h5进行适当的转化并配置到android工程中,我们查询了许多相关文档与技术blog。
此前已经很清楚的是,Keras是对TensorFlow的一种封装,是运行在TensorFlow的基础之上的(当然也可以基于Theano,缺省是基于TensorFlow)。在运行Keras模型的时候,能够看到TensorFlow Backend的提示。昨天下午对于此部分任务已经进行了一些了解,我们对keras中建立的模型对象的load_weight()方法已经很熟悉了,但是苦于找不到调用具体对象的TensorFlow Backend的方法。今天上午我们找到了一些文章,其中提到了keras.backend类。我们甚至连import keras.backend as K都写了,但是就是差一步,还是不知道如何将这个backend与keras对象联系在一起,也就无法获取模型构建的session。然后我就瞎写一通,写了一些明明知道是错的命令,解决了一些无所谓解决不解决的bug,居然也得到了pb文件和ckpt文件,但是显然它们不太可能是正确的文件。我虽然没弄清如何将backend对象与keras对象联系在一起,却弄清了如何在TensorFlow下调用keras创建的model,定义一个tf的占位符x,然后让y=model(x)即可调用。
助教来了以后,我们得知了一个获取对象的方法列表的函数dir(),我看到这个的时候内心os:“还有这种操作?”我们找到了get_session()方法,这个方法返回一个运行着的缺省的keras对象的backend,也就等效于一个TensorFlow对象,这正是运行着的keras对象的backend;再看get_session()所包含的方法与属性,发现有graph和graph_def,这正是我们需要的东西。但是backend本身是不能等价于TensorFlow的,只有backend对象的get_session()返回的值才能等价于TensorFlow对象。
有了这种操作,获取所需文件就是很轻松的事情了。当然,需要注意的是,saver类本身不包含save(),只有Saver对象/实例才能调用save()。而后freeze的过程,也是比较容易的,排除几个语法错误即可。我们所有的命令都是直接在python或cmd里逐句输入执行的,不过最后我还是整理了出了脚本,以便日后回忆用。
获取pb文件和ckpt文件:
#generate model.pb
from model import KerasModel
import keras.backend as K
from tensorflow.python.training import saver
model = KerasModel()
model.load_weights('save_51.h5') #use the model from round 52
gDef = K.get_session().graph_def
with open('model.pb', 'wb') as f:
f.write(gDef.SerializeToString())
#generate model.ckpt
saver.Saver().save(K.get_session(), 'model.ckpt')
冻图命令如下,在cmd中执行,需要预先将freeze_graph.py拷贝至执行根目录下。前四个参数是强制的,后一个参数缺省值是False,由于我们的pb文件是二进制,所以要设置为True,否则无法decode。所有的参数都不能有任何引号包括。
python freeze_graph.py --input_graph=model.pb --input_checkpoint=model.ckpt --output_graph=asrModel.pb --output_node_names=dense_2/Softmax --input_binary=True
为得到output_node_names,我们可以在model.py中添加一句代码,然后找到相应输出即可。
... #x = Dropout(DROP_RATE)(x) x = Dense(24, activation='softmax')(x) print(x.name) #add this line model = Model(input=In, output=x) ...
最后部署到android工程里就非常轻松。但是结果略有点鬼畜,我们训练了这么久的模型,最终得到了一个人工智障。在实验室环境下,如果很认真地发音,那么识别准确率在百分之九十以上;只要说得稍微随便一些,识别基本上就会错误,这和此前的模型的效果相去甚远,多半是训练过程出了问题。助教和我们排查了一系列问题,包括学习轮次、批次样本数目、是否过学习等等,结果并没有发现设置不正常的地方。又检查了sox工作是否正常,发现样本在加载后的确都被正常修饰了,按理来说训练效果应该很好。我们修改脚本,从第十轮的文件开始跑训练,发现第十轮的accuracy虽然已经0.9+,但是val_acc也就是test出的accuracy却只有0.064,这个值直到训练的最后基本都没有变化过,甚至还降低了,这非常令人困惑,需要之后再继续探究原因了。
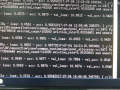
极低的val_acc

Summary
TensorFlow这个深度学习的工具,我也不是第一次听说了,去年在做一个小项目的编写的时候就了解到这个工具,但是当时觉得深度学习的门槛很高,也就没有深入了解。这次体验最大的收获,就是发现了TensorFlow给我们带来的无限可能性与易用性。谷歌出品,必属精品。虽然关于人工神经网络的理论必定是高深的,但是可用于实际应用的模型却并没有特别高的门槛。当硬件开发都走向了高中生初中生的课堂的时候,深度学习也即将大规模进入大学研究者的课题了,现在可能还处于起步阶段,未来发展一定迅速。仅仅就我们专业来说,在医学影像识别上,神经网络必然成为下一个热点,而系统神经科学的研究就更加不用说了,人工智能与神经科学本来就是相互促进的。神经网络的研究与应用值得我们去关注。
当然,还要清楚地认识到,仅仅有工具、会用工具是不行的。通用型的神经网络以外的部分才是最核心的构建——将学习对象的数据转化为神经网络能够处理的张量的算法、使用何种神经网络的结构才能充分解析一类数据的特征、如何选取合适的输入与网络来匹配有限的算力。甚至说,仅仅做到将数据转化并输入神经网络也是不够的,如果算法不够好,可能会丢失大量的信息,学习再久也没有任何意义;学习的参数调试得不恰当,也会导致学习没有成效,有时候就算没有显性的错误,也可能导致效果极差,这一次我们训练的模型就是一个例子。神经网络提供的可能性太多了,所以使用的它的难度也绝对不小,这对我们来说才是真正的挑战。
当然,还有点非主题的东西,就是关于python的。说实话,python无论是写起来还是读起来都太舒服了,代码不冗余,接近自然语言,尤其是强制缩进,简直是强迫症的福音,我觉得可以将它作为主力语言去学习一下了。