“2016012144”版本间的差异
Vitor Shen(讨论 | 贡献) (→文字記錄) |
|||
| (2位用户的41个中间修订版本未显示) | |||
| 第1行: | 第1行: | ||
| + | 沈偉棟學習日誌記錄(以日子分隔) | ||
| + | ==2017年6月29日== | ||
| + | 这一天主要聆听老师介绍智能硬件、PYNQ、Tensorflow(当天安装),以及解答交待了我们的目标是要做出最后的语音识别的成果。 | ||
| + | ==2017年6月30日== | ||
| + | ===文字記錄=== | ||
| + | 主要完成pynq板调试与安装,其中主要花了較長時間在安裝PYNQ上。 | ||
| + | 根据老师说指导我们并提供了在pyno.io上的PYNQ入门指南进行初步 | ||
| + | 的简介,主要硬件为PYNQ开发板、SD卡以及网线等。 | ||
| + | 其中,安装时也需要安装到Python语言程式以及利用Jupyter进行各种调节,详情可参与pyno.io上的官方指南。 | ||
| + | 这天,我对于PYNQ这个“微型电脑”开始有了初步了解,感到很神奇并且在安装完成时有一点期待。 | ||
| + | ===圖片記錄=== | ||
| + | 以下为PYNQ开发板之图<br/> | ||
| + | [[文件:20170701_082447.jpg|无框]] | ||
| − | + | ==2017年7月1日== | |
| + | ===文字記錄=== | ||
| + | *上午主要实验了 PYNQ 中 USB Webcam 与 OpenCV Filters Webcam 功能的实现 | ||
| + | *下午主要对TensowFlow tfExample进行操作性练习以试图熟悉与理解 | ||
| + | 在tfExample中进行了TensorBoard展示的操作试验:TensorBoard是TensorFlow自带的图形化工具,可以展示出网络训练(内部权重和偏振)的效果,使用了MNIST数据集的训练过程并以TensorBoard展示。 | ||
| + | <br /> | ||
| + | 通过这些天,尤其这天,对于本来基本上没有学过编程(一看就觉得无所适从的我)来说是个好的开始,只少在操作中透过老师们与同学们的协助与交流后令我有了大致的体会。以及也能看出PYNQ这个“电脑”里的各种功能对于原本需要复杂程序运行的简化使使用者/开发者能更简便地编码指令(包括用到Python语言,TensorFlow系统)。 | ||
| + | <br /> | ||
| + | *值得一提的是:当天老师跟我们讲解了Deep Learning -tutorial 的一些基本概念与原理,以及关于神经网络训练的相关内容。 | ||
| + | <br /> | ||
| + | ===圖片記錄=== | ||
| + | *以下为PYNQ 中 USB Webcam 与 OpenCV Filters Webcam 功能的效果图 | ||
| + | <gallery> | ||
| + | 文件:2017-07-01.png|OpenCV Filters Webcam | ||
| + | 文件:2017-07-01 (2).png|USB Webcam (包括灰度图与旋转) | ||
| + | </gallery> | ||
| + | 其中 | ||
| + | <gallery> | ||
| + | 文件:Download1.png|OpenCV Filters Webcam | ||
| + | 文件:Download-1.png|USB Webcam (原图) | ||
| + | 文件:Download-2.png|USB Webcam (灰度图) | ||
| + | 文件:Download-3.png|USB Webcam (旋转图) | ||
| + | </gallery> | ||
| + | <br /> | ||
| + | *可见按PYNQ中范例语句实验操作效果如下: | ||
| + | [[文件:2017-07-01.png|无框]] | ||
| + | [[文件:2017-07-01 (2).png|无框]] | ||
| + | <br /> | ||
| + | [[文件:Download1.png|无框]] | ||
| + | <br /> | ||
| + | [[文件:Download-2.png|无框]] | ||
| + | [[文件:Download-3.png|无框]] | ||
| + | <br /> | ||
| + | <br /> | ||
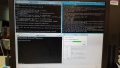
| + | *以下为TensorBoard展示MNIST数据训练结果 | ||
| + | [[文件:20170701 203504.jpg|无框]] | ||
| − | + | ==2017年7月2日== | |
| + | ===文字記錄=== | ||
| + | *机器学习、数据训练 | ||
| + | 当天,早上在动手实验操作学习体验方面,进行了两个主要部分: | ||
| + | 其一关于Keras实践。Keras简单来说便是TensorFlow的封装并进一步集成Keras框架并由此达到机器学习模型、训练、预测的过程。 | ||
| + | 简单地了解和尝试网络训练后到下一环节,可谓本日主要的“重头戏”。 | ||
| − | + | 也就是其二:关于语音识别网络这一主要部分(本挑战学习核心内容),经过老师指导,简单了解和学习到语言识别网络中较为简单的三层全连接网络和比较准确率更优的CLDNN网络 | |
| − | + | 然后,铺垫过后主要是进行TensorFlow/ Keras的使用 并最终其实期望大致训练的效果。 | |
| − | + | 当中,大致的操作流程为:在Tsinghua i-Center的gitlab资源里下载提供的代码、并有老师提供音频数据(被调整统一为.wave ,且经过加干扰在原本为数不多的音频基础上获得大量!),然后在获得的文件夹audioNet里开始操作。在创建目录和修改代码后,开始进行训练——在该目标档案文件夹里运行python train.py 以及python client.py, 当中遇到了一些问题,包括cudnn的版本未成功被识别为装好(装了6不行而要5...)以及一些档案补充使得环境适当(cuda,cudnn合适存在对gpu起作用)可以进行Trainning,结果为需要运行大批数据,几乎整个下午(粗略估计大于2小时),明天应当有结果(生成一系列文件),并继续观察。这就令我初步见识到神经网络训练的过程了(非常初阶)! | |
| − | | | + | *值得一提的是:这天我们继续有老师再讲解深度学习原理以及一些(对我来说陌生的词)激活函数,人工神经网络,损失函数的量化输出结果和实际结果的差距,常用调节权重的方法中随机梯度下降法,一些Deep Learning的常用术语等。 |
| − | |- | + | |
| − | | | + | ===圖片記錄=== |
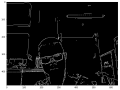
| + | 以下为训练过程摄影图片: | ||
| + | <gallery> | ||
| + | 文件:20170702_115247.jpg|一开始版本问题报错 | ||
| + | 文件:20170702_172002.jpg|最终成功运行训练中 | ||
| + | </gallery> | ||
| + | |||
| + | ==2017年7月3日== | ||
| + | ===文字記錄=== | ||
| + | * 主要初步实现在基于Android系统而在手机上实现“由语音识别成文字” | ||
| + | 本日主要为在Android系统手机上实现语音识别,使用Android studio编写程序(其中老师也有提供一些和指引),并根据早前人们录音的数据和训练的结果的基础下进行简单的语音识别(共24句,当中以噪音形式增加了原本为数不多的声音样本,如昨天说记载)。 | ||
| + | 其中,利用到Keras, Tensorflow, Android Studio等程式,而代码则由已给予及经过老师指导与给与的资源指引下自己尝试操作并最终经由Android Studio生成一个.apk文件以在手机上实现App形式的以文字形式输出的语音识别。在老师提供的资源中有很多执行命令与代码,并不全然理解,但定性来看可归难出其初衷。在运行过程中,遇到了一些大小问题,简单的其实只要保持冷静在过程中调整过来回头再看大多便可发现不妥,与其他同学们请教与交流也是良好的团队意识过程的阶段。过程中最大感受便是在一些意外时,向大家主动询问是需要的,不过前提当然是要在冷静下来分析过后才去。而且,有这个过程中我明白到太心急慌乱地一直做,倒不如调整一下,再仔细检查与思考现在的目标更为重要,可见很多时候“调整状态”是非常重要的。(BTW对我来说遇到电脑编程相关的东西是超出我“现时认知范围”的、尽管没有真正学过,但这并不是理所当然的借口,唯有尽量记忆与理解为开始再配以体会教程中的说明与实际操作加上与人们的交流被加指导过程中尝试得以进步~) | ||
| + | 最后在,经过上下午的安装环境、调试程序等操作,终于在前人(以往同学老师)的资源贡献下,生成了成功的在手机运行的“语音识别”Android App。 | ||
| + | <br/> | ||
| + | *值得一提的是,回顾这一天,在整理提供与指引的代码及使用Android Studio的指导流程后,由于我使用的Samsung Galaxy 型号手机出了一些未知/未被解决问题而连接电脑时没有侦测到(也就是无法像教程那样进入开发者模式下进行USB debugging模型运行并生成app),所以在大家都以教案的方法USB调试完成后,我让继续留了一段时间,做了一些调整与测试,最终返回初衷,在Android Studio那里的Build功能里有直接Build apk的运作并成功以另一途径解决了问题(我把生成的.apk档案上传到云端再从手机下载使用【也许不是很有效率的方法,但至少是在一个阶段的顺利过渡临时方案】)。 | ||
| + | |||
| + | ===圖片記錄=== | ||
| + | *其中,App在手机的状况如下图 | ||
| + | (此为由声音识别后输出的结果——文字) | ||
| + | <br/> | ||
| + | [[文件:Screenshot 20170704-005659.png|无框]] | ||
| + | |||
| + | ==2017年7月4日== | ||
| + | 到了挑战环节的最后一天~ | ||
| + | ===文字記錄=== | ||
| + | *主要为利用自己训练和生成的model作语音识别的App | ||
| + | 承接着昨天成功地“开发”出语音识别的Android app,这天在前人的基础上最新加入了我们本次挑战同学们的“蓝牙声音”在样本中,并经过训练生成的结果透过在Tensorflow创建好的网络模型下生成最终的model.pb文件后,也利用到freeze冻图的手法(把变量转换为常数constant以解决variable变量无法被储存的问题,在tensorflow的python/tool上有提供)后,把最终生成可用的model.py替代昨天的asrModel.pb并在手机上测试后果。遗憾的是这个model下的识别准确度比较不理想,多次都不准确反映语音文字,后来在助教与同学们一起交流讨论找问题时探讨过各种可能性,但是最终还是由于找到了一直大家只关注的训练中的accuracy,而实际测试accuracy不到10%,其中印象中在交流中的有一可能性为每次的训练样本数太少...... | ||
| + | *值得一提的是:查看了一下之前训练的进程,经过了一天多的训练,已有100轮了,train的accuracy高于0.9,但问题如以上已提到。 | ||
| + | |||
| + | ===圖片記錄=== | ||
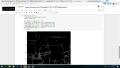
| + | 以下为最终基于助教指导下的整个流程的code python编码 | ||
| + | <br/> | ||
| + | [[文件:2017-07-04 (2).png|无框]] | ||
| + | |||
| + | ==小结== | ||
| + | 经过了这5天多的时间...() | ||
| + | *我和项目中的同学们共同以最“亲临其境”的手法体验了神经网络Deep Learning & Trainging等模块知识 | ||
| + | *在过程中也顺带在必须使用python语句稍微理解了一些“编程”手法以及最简单“如何执行命令/语句”(我认为是意外地非常大的收获) | ||
| + | *犹如在一个小团队中在一个房间一起努力为共同目标而投入并交流、请教和思考的乐趣与重要过程 | ||
| + | *简单理解与体会计算机行业以及人工智能中智能硬件这一领域的具有具突破性的前瞻性与实用性 | ||
| + | *期望我之后也许再继续“消化”一下过程里内容中的一些细节(毕竟时间不长) | ||
2017年7月4日 (二) 18:03的最后版本
沈偉棟學習日誌記錄(以日子分隔)
目录
2017年6月29日
这一天主要聆听老师介绍智能硬件、PYNQ、Tensorflow(当天安装),以及解答交待了我们的目标是要做出最后的语音识别的成果。
2017年6月30日
文字記錄
主要完成pynq板调试与安装,其中主要花了較長時間在安裝PYNQ上。 根据老师说指导我们并提供了在pyno.io上的PYNQ入门指南进行初步 的简介,主要硬件为PYNQ开发板、SD卡以及网线等。 其中,安装时也需要安装到Python语言程式以及利用Jupyter进行各种调节,详情可参与pyno.io上的官方指南。 这天,我对于PYNQ这个“微型电脑”开始有了初步了解,感到很神奇并且在安装完成时有一点期待。
圖片記錄
以下为PYNQ开发板之图

2017年7月1日
文字記錄
- 上午主要实验了 PYNQ 中 USB Webcam 与 OpenCV Filters Webcam 功能的实现
- 下午主要对TensowFlow tfExample进行操作性练习以试图熟悉与理解
在tfExample中进行了TensorBoard展示的操作试验:TensorBoard是TensorFlow自带的图形化工具,可以展示出网络训练(内部权重和偏振)的效果,使用了MNIST数据集的训练过程并以TensorBoard展示。
通过这些天,尤其这天,对于本来基本上没有学过编程(一看就觉得无所适从的我)来说是个好的开始,只少在操作中透过老师们与同学们的协助与交流后令我有了大致的体会。以及也能看出PYNQ这个“电脑”里的各种功能对于原本需要复杂程序运行的简化使使用者/开发者能更简便地编码指令(包括用到Python语言,TensorFlow系统)。
- 值得一提的是:当天老师跟我们讲解了Deep Learning -tutorial 的一些基本概念与原理,以及关于神经网络训练的相关内容。
圖片記錄
- 以下为PYNQ 中 USB Webcam 与 OpenCV Filters Webcam 功能的效果图
OpenCV Filters Webcam
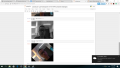
USB Webcam (包括灰度图与旋转)
其中
OpenCV Filters Webcam

USB Webcam (原图)

USB Webcam (灰度图)

USB Webcam (旋转图)


- 可见按PYNQ中范例语句实验操作效果如下:

.png)



- 以下为TensorBoard展示MNIST数据训练结果

2017年7月2日
文字記錄
- 机器学习、数据训练
当天,早上在动手实验操作学习体验方面,进行了两个主要部分: 其一关于Keras实践。Keras简单来说便是TensorFlow的封装并进一步集成Keras框架并由此达到机器学习模型、训练、预测的过程。 简单地了解和尝试网络训练后到下一环节,可谓本日主要的“重头戏”。
也就是其二:关于语音识别网络这一主要部分(本挑战学习核心内容),经过老师指导,简单了解和学习到语言识别网络中较为简单的三层全连接网络和比较准确率更优的CLDNN网络 然后,铺垫过后主要是进行TensorFlow/ Keras的使用 并最终其实期望大致训练的效果。 当中,大致的操作流程为:在Tsinghua i-Center的gitlab资源里下载提供的代码、并有老师提供音频数据(被调整统一为.wave ,且经过加干扰在原本为数不多的音频基础上获得大量!),然后在获得的文件夹audioNet里开始操作。在创建目录和修改代码后,开始进行训练——在该目标档案文件夹里运行python train.py 以及python client.py, 当中遇到了一些问题,包括cudnn的版本未成功被识别为装好(装了6不行而要5...)以及一些档案补充使得环境适当(cuda,cudnn合适存在对gpu起作用)可以进行Trainning,结果为需要运行大批数据,几乎整个下午(粗略估计大于2小时),明天应当有结果(生成一系列文件),并继续观察。这就令我初步见识到神经网络训练的过程了(非常初阶)!
- 值得一提的是:这天我们继续有老师再讲解深度学习原理以及一些(对我来说陌生的词)激活函数,人工神经网络,损失函数的量化输出结果和实际结果的差距,常用调节权重的方法中随机梯度下降法,一些Deep Learning的常用术语等。
圖片記錄
以下为训练过程摄影图片:
一开始版本问题报错
最终成功运行训练中


2017年7月3日
文字記錄
- 主要初步实现在基于Android系统而在手机上实现“由语音识别成文字”
本日主要为在Android系统手机上实现语音识别,使用Android studio编写程序(其中老师也有提供一些和指引),并根据早前人们录音的数据和训练的结果的基础下进行简单的语音识别(共24句,当中以噪音形式增加了原本为数不多的声音样本,如昨天说记载)。
其中,利用到Keras, Tensorflow, Android Studio等程式,而代码则由已给予及经过老师指导与给与的资源指引下自己尝试操作并最终经由Android Studio生成一个.apk文件以在手机上实现App形式的以文字形式输出的语音识别。在老师提供的资源中有很多执行命令与代码,并不全然理解,但定性来看可归难出其初衷。在运行过程中,遇到了一些大小问题,简单的其实只要保持冷静在过程中调整过来回头再看大多便可发现不妥,与其他同学们请教与交流也是良好的团队意识过程的阶段。过程中最大感受便是在一些意外时,向大家主动询问是需要的,不过前提当然是要在冷静下来分析过后才去。而且,有这个过程中我明白到太心急慌乱地一直做,倒不如调整一下,再仔细检查与思考现在的目标更为重要,可见很多时候“调整状态”是非常重要的。(BTW对我来说遇到电脑编程相关的东西是超出我“现时认知范围”的、尽管没有真正学过,但这并不是理所当然的借口,唯有尽量记忆与理解为开始再配以体会教程中的说明与实际操作加上与人们的交流被加指导过程中尝试得以进步~)
最后在,经过上下午的安装环境、调试程序等操作,终于在前人(以往同学老师)的资源贡献下,生成了成功的在手机运行的“语音识别”Android App。
- 值得一提的是,回顾这一天,在整理提供与指引的代码及使用Android Studio的指导流程后,由于我使用的Samsung Galaxy 型号手机出了一些未知/未被解决问题而连接电脑时没有侦测到(也就是无法像教程那样进入开发者模式下进行USB debugging模型运行并生成app),所以在大家都以教案的方法USB调试完成后,我让继续留了一段时间,做了一些调整与测试,最终返回初衷,在Android Studio那里的Build功能里有直接Build apk的运作并成功以另一途径解决了问题(我把生成的.apk档案上传到云端再从手机下载使用【也许不是很有效率的方法,但至少是在一个阶段的顺利过渡临时方案】)。
圖片記錄
- 其中,App在手机的状况如下图
(此为由声音识别后输出的结果——文字)

2017年7月4日
到了挑战环节的最后一天~
文字記錄
- 主要为利用自己训练和生成的model作语音识别的App
承接着昨天成功地“开发”出语音识别的Android app,这天在前人的基础上最新加入了我们本次挑战同学们的“蓝牙声音”在样本中,并经过训练生成的结果透过在Tensorflow创建好的网络模型下生成最终的model.pb文件后,也利用到freeze冻图的手法(把变量转换为常数constant以解决variable变量无法被储存的问题,在tensorflow的python/tool上有提供)后,把最终生成可用的model.py替代昨天的asrModel.pb并在手机上测试后果。遗憾的是这个model下的识别准确度比较不理想,多次都不准确反映语音文字,后来在助教与同学们一起交流讨论找问题时探讨过各种可能性,但是最终还是由于找到了一直大家只关注的训练中的accuracy,而实际测试accuracy不到10%,其中印象中在交流中的有一可能性为每次的训练样本数太少......
- 值得一提的是:查看了一下之前训练的进程,经过了一天多的训练,已有100轮了,train的accuracy高于0.9,但问题如以上已提到。
圖片記錄
以下为最终基于助教指导下的整个流程的code python编码
.png)
小结
经过了这5天多的时间...()
- 我和项目中的同学们共同以最“亲临其境”的手法体验了神经网络Deep Learning & Trainging等模块知识
- 在过程中也顺带在必须使用python语句稍微理解了一些“编程”手法以及最简单“如何执行命令/语句”(我认为是意外地非常大的收获)
- 犹如在一个小团队中在一个房间一起努力为共同目标而投入并交流、请教和思考的乐趣与重要过程
- 简单理解与体会计算机行业以及人工智能中智能硬件这一领域的具有具突破性的前瞻性与实用性
- 期望我之后也许再继续“消化”一下过程里内容中的一些细节(毕竟时间不长)